%%capture
!pip install pytorch-lightning
!pip install torchmetricsEffective LSTMs for Target Dependent Sentiment Classification [Part 2]
Tutorials / Implementations
NLP
Reproduce the ‘Effective LSTMs for Target Dependent Sentiment Classification’ paper.
The full notebook is available here.
Install required packages
Import required packages
import pickle
from collections import Counter, OrderedDict
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple, Union
from urllib.request import urlretrieve
import numpy as np
from tqdm import tqdm
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchmetrics
import torchtext
from pytorch_lightning import loggers as pl_loggers
from pytorch_lightning.callbacks import ModelCheckpoint
from torch.nn.utils.rnn import (pack_padded_sequence, pad_packed_sequence,
pad_sequence)
from torch.utils.data import DataLoader, Dataset, random_split
from torchtext.data import get_tokenizer
from torchtext.vocab import Vectors, Vocab
# For repoducibility
pl.utilities.seed.seed_everything(seed=2401, workers=True)Global seed set to 24012401Define dataset, data module class, utils function
=====Dataset File Format=====
Each instance consists three lines: - sentence (the target is replaced with \(T\)) - target - polarity label (0: neutral, 1:positive, -1:negative)
Example:
i agree about arafat . i mean , shit , they even gave one to \(T\) ha . it should be called ’’ the worst president ’’ prize .
jimmy carter
-1
# Read file
class TqdmUpTo(tqdm):
"""From https://github.com/tqdm/tqdm/blob/master/examples/tqdm_wget.py"""
def update_to(self, blocks=1, bsize=1, tsize=None):
"""
Parameters
----------
blocks: int, optional
Number of blocks transferred so far [default: 1].
bsize: int, optional
Size of each block (in tqdm units) [default: 1].
tsize: int, optional
Total size (in tqdm units). If [default: None] remains unchanged.
"""
if tsize is not None:
self.total = tsize # pylint: disable=attribute-defined-outside-init
self.update(blocks * bsize - self.n) # will also set self.n = b * bsize
class Tokenizer():
def __init__(self, tokenizer: Any):
self.counter = Counter(['<pad>', '<unk>'])
self.tokenizer = tokenizer
self.vocab = self.update_vocab()
def update_vocab(self):
sorted_by_freq_tuples = sorted(self.counter.items(), key=lambda x: x[1], reverse=True)
ordered_dict = OrderedDict(sorted_by_freq_tuples)
self.vocab = torchtext.vocab.vocab(ordered_dict, min_freq=1)
self.vocab.set_default_index(self.vocab['<unk>'])
def fit_on_texts(self, texts: List[str]):
"""
Updates internal vocabulary based on a list of texts.
"""
# lower and tokenize texts to sequences
for text in texts:
self.counter.update(self.tokenizer(text))
# self.counter.update([t.lower().strip() for t in text.split()])
self.update_vocab()
def texts_to_sequences(self, texts: List[str], reverse: bool=False, tensor: bool=True) -> List[int]:
sequences = []
for text in texts:
seq = [self.vocab[word] for word in self.tokenizer(text)]
if reverse:
seq = seq[::-1]
if tensor:
seq = torch.tensor(seq)
sequences.append(seq)
return sequences
def _load_data_from(path: Union[str, Path]) -> Tuple[List[List[str]], List[List[str]], List[set]]:
"""
Create a dataset from a file path
Return: a TwitterDataset object
"""
sentences = []
targets = []
sentiments = []
with open(path) as f:
lines = f.readlines()
# Read the file line by line and
# check the relative index to parse the data according to the format.
for i, line in enumerate(lines):
index = i % 3 # compute the relative index
if index == 0: sentences.append(line[:-1])
elif index == 1: targets.append(line[:-1])
elif index == 2: sentiments.append(line.strip())
return sentences, targets, sentiments
def download_url(url, filename, directory='.'):
"""Download a file from url to filename, with a progress bar."""
if not os.path.exists(directory):
os.makedirs(directory)
path = os.path.join(directory, filename)
with TqdmUpTo(unit="B", unit_scale=True, unit_divisor=1024, miniters=1) as t:
urlretrieve(url, path, reporthook=t.update_to, data=None) # nosec
return path
def _preprocess_data(data, tokenizer):
sents, targets, sentiments = data
l_texts = []
r_texts = []
texts = []
for i, sent in enumerate(sents):
l_text, _, r_text = sent.partition("$T$")
l_text = l_text + ' ' + targets[i]
r_text = targets[i] + ' ' + r_text
text = l_text + ' ' + targets[i] + ' ' + r_text
l_texts.append(l_text)
r_texts.append(r_text)
texts.append(text)
# Generate left, right and target sequences
l_sequences = tokenizer.texts_to_sequences(l_texts)
r_sequences = tokenizer.texts_to_sequences(r_texts, reverse=True)
target_sequences = tokenizer.texts_to_sequences(targets)
sequences = tokenizer.texts_to_sequences(texts)
# Calcuate length of each sequence in the left, right sequences
l_lens = torch.tensor([len(seq) for seq in l_sequences])
r_lens = torch.tensor([len(seq) for seq in r_sequences])
lens = torch.tensor([len(seq) for seq in sequences])
# Padding sequences
l_sequences = pad_sequence(l_sequences, batch_first=True)
r_sequences = pad_sequence(r_sequences, batch_first=True)
target_sequences = pad_sequence(target_sequences, batch_first=True)
sequences = pad_sequence(sequences, batch_first=True)
#Convert sentiment text to number
sentiments = list(map(lambda x: int(x), sentiments))
sentiments = torch.tensor(sentiments) + 1 # increment labels by 1
# Double Checking
assert len(r_lens) == len(r_sequences)
assert len(l_lens) == len(l_sequences)
assert len(l_lens) == len(sentiments)
data = []
for i in range(len(sentiments)):
sample = {
'padded_l_sequence': l_sequences[i],
'padded_r_sequence': r_sequences[i],
'padded_sequence': sequences[i],
'l_len': l_lens[i],
'r_len': r_lens[i],
'len': lens[i],
'padded_target_sequence': target_sequences[i],
'sentiment': sentiments[i]
}
data.append(sample)
return data
def build_vocab(tokenizer, data):
sentences, targets = data
texts = []
for i, sent in enumerate(sentences):
texts.append(sent.replace('$T$', targets[i]))
tokenizer.fit_on_texts(texts)
def load_pretrained_word_embeddings(options: Dict[str, Any]):
return torchtext.vocab.GloVe(options['name'], options['dim'])
def create_embedding_matrix(word_embeddings: Vectors, vocab: Vocab, path: Union[str, Path]):
if os.path.exists(path):
print(f'loading embedding matrix from {path}')
embedding_matrix = pickle.load(open(path, 'rb'))
else:
embedding_matrix = torch.zeros((len(vocab), word_embeddings.dim),
dtype=torch.float)
# words that are not availabel in the pretrained word embeddings will be zeros
for word, index in vocab.get_stoi().items():
embedding_matrix[index] = word_embeddings.get_vecs_by_tokens(word)
# save embedding matrix
pickle.dump(embedding_matrix, open(path, 'wb'))
return embedding_matrixclass TwitterDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
TRAIN_DS_URL = "https://raw.githubusercontent.com/songyouwei/ABSA-PyTorch/master/datasets/acl-14-short-data/train.raw"
TEST_DS_URL = "https://raw.githubusercontent.com/songyouwei/ABSA-PyTorch/master/datasets/acl-14-short-data/test.raw"
class Twitter(pl.LightningDataModule):
"""
The Twitter dataset is ndwritten character digits derived from the NIST Special Database 19
"""
def __init__(self, tokenizer: Tokenizer, opts: Dict[str, Any]):
super().__init__()
self.tokenizer = tokenizer
self.batch_size = opts['batch_size']
self.num_workers = opts['num_workers']
self.on_gpu = opts['on_gpu']
self.mapping = {"negative": 0, "neutral": 1, "positive": 2}
self.inverse_mapping = {v: k for k, v in enumerate(self.mapping)}
def prepare_data(self, *args, **kwargs) -> None:
# Download the data
train_path = "download/raw_data/train.raw"
test_path = "download/raw_data/test.raw"
if not os.path.exists(train_path):
self.train_path = download_url(TRAIN_DS_URL, "train.raw", "download/raw_data")
else:
self.train_path = train_path
if not os.path.exists(test_path):
self.test_path = download_url(TEST_DS_URL, "test.raw", "download/raw_data")
else:
self.test_path = test_path
def setup(self, stage: str = None) -> None:
if stage == 'fit' or stage is None:
# Load data from file
train_data = _load_data_from(self.train_path)
test_data = _load_data_from(self.test_path)
# Preprocess data
self.train_data = _preprocess_data(train_data, self.tokenizer)
self.test_data = _preprocess_data(test_data, self.tokenizer)
# In the paper, the author use the test set as validation set
self.val_data = self.test_data
elif stage == 'test':
test_data = _load_data_from(self.test_path)
self.test_data = _preprocess_data(test_data, self.tokenizer)
def train_dataloader(self):
# Create Dataset object
train_ds = TwitterDataset(self.train_data)
# Create Dataloader
return DataLoader(
train_ds,
shuffle=True,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.on_gpu,
)
def val_dataloader(self):
val_ds = TwitterDataset(self.val_data)
return DataLoader(
val_ds,
shuffle=False,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.on_gpu,
)
def test_dataloader(self):
test_ds = TwitterDataset(self.test_data)
return DataLoader(
test_ds,
shuffle=False,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.on_gpu,
)
def __repr__(self):
basic = f"Twitter Dataset\nNum classes: {len(self.mapping)}\nMapping: {self.mapping}\n"
if self.train_data is None and self.val_data is None and self.test_data is None:
return basic
x, y = next(iter(self.train_dataloader()))
data = (
f"Train/val/test sizes: {len(self.train_data)}, {len(self.val_data)}, {len(self.test_data)}\n"
f"Batch x stats: {(x.shape, x.dtype)}\n"
f"Batch y stats: {(y.shape, y.dtype)}\n"
)
return basic + dataIn the paper, the author trained the model on training set, and evaluated the performance on test set
Implement Model Architecture
We use Adam as our optimizer and using accuracy and f1 as our evaluating metrics, just like in the original paper. Also, we use cross entropy function to calculate our loss, which is the de-facto function for multi-class classification task.
TD-LSTM
The architecture has a embedding layer, 2 LSTM layers and 1 dense layer.
- Embedding layer:
Convert the sequences to word vectors using pre-trained Glove word embeddings
- 2 LSTM layers:
One layer is used for the [left context + target] sequences, and one is used for the [target + right context] sequences.
- Dense layer:
We concate the 2 hidden states from the LSTM layers and feed it into the Dense layer.
To take into account of the target information, we make a slight modification on the \(LSTM\) model. The basic idea is to model the preceding and following contexts surrounding the target string, so that contexts in both directions could be used as feature representations for sentiment classification. We believe that capturing such target-dependent context information could improve the accuracy of target-dependent sentiment classification.
Specifically, we use two \(LSTM\) neural networks, a left one \(LSTM_L\) and a right one \(LSTM_R\), to model the preceding and following contexts respectively. An illustration of the model is shown in Figure 1. The input of \(LSTM_L\) is the preceding contexts plus target string, and the input of \(LSTM_R\) is the following contexts plus target string. We run \(LSTM_L\) from left to right, and run \(LSTM_R\) from right to left. We favor this strategy as we believe that regarding target string as the last unit could better utilize the semantics of target string when using the composed representation for sentiment classification. Afterwards, we concatenate the last hidden vectors of \(LSTM_L\) and \(LSTM_R\) , and feed them to a sof tmax layer to classify the sentiment polarity label. One could also try averaging or summing the last hidden vectors of \(LSTM_L\) and \(LSTM_R\) as alternatives.
from IPython.display import Image
Image(filename='images/figure_1_image.png')
class TDLSTM(pl.LightningModule):
def __init__(self, embeddings, hidden_size, num_layers=1, num_classes=3, batch_first=True, lr=1e-3, dropout=0, l2reg=0.01):
super().__init__()
embedding_dim = embeddings.shape[1]
self.embedding = nn.Embedding.from_pretrained(embeddings) # load pre-trained word embeddings
self.l_lstm = nn.LSTM(embedding_dim, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.r_lstm = nn.LSTM(embedding_dim, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.linear = nn.Linear(hidden_size*2, num_classes)
self.lr = lr
self.l2reg = l2reg
# Define metrics
self.train_acc = torchmetrics.Accuracy()
self.val_acc = torchmetrics.Accuracy()
self.val_f1 = torchmetrics.F1(num_classes=3, average='macro')
self.test_acc = torchmetrics.Accuracy()
self.test_f1 = torchmetrics.F1(num_classes=3, average='macro')
def configure_optimizers(self):
optim = torch.optim.Adam(self.parameters(), lr=self.lr, weight_decay=self.l2reg)
return optim
def forward(self, data):
cols = ['padded_l_sequence', 'padded_r_sequence', 'l_len', 'r_len']
padded_l_seqs, padded_r_seqs, l_lens, r_lens = [data[col] for col in cols]
# convert seq to word vector
padded_l_embeds = self.embedding(padded_l_seqs)
padded_r_embeds = self.embedding(padded_r_seqs)
# pack the embeds
padded_l_seq_pack = pack_padded_sequence(padded_l_embeds, l_lens.cpu(), batch_first=True, enforce_sorted=False)
padded_r_seq_pack = pack_padded_sequence(padded_r_embeds, r_lens.cpu(), batch_first=True, enforce_sorted=False)
_, (h_l, _) = self.l_lstm(padded_l_seq_pack)
_, (h_r, _) = self.r_lstm(padded_r_seq_pack)
h = torch.cat((h_l[-1], h_r[-1]), -1) # B x 2H
out = self.linear(h)
return out
def training_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.train_acc(scores, sentiments)
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('train_acc', self.train_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.val_acc(scores, sentiments)
self.val_f1(scores, sentiments)
self.log('val_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('val_acc', self.val_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
self.log('val_f1', self.val_f1, on_step=False, on_epoch=True, prog_bar=True, logger=True)
def test_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
scores = F.softmax(logits, dim=-1)
self.test_acc(scores, sentiments)
self.test_f1(scores, sentiments)
self.log('test_acc', self.test_acc, on_step=False, on_epoch=True, logger=True)
self.log('test_f1', self.test_f1, on_step=False, on_epoch=True, logger=True)TC-LSTM
The architecture has a embedding layer, 2 LSTM layers and 1 dense layer.
- Embedding layer:
Convert the sequences to word vectors using pre-trained Glove word embeddings
- 2 LSTM layers:
One layer is used for the [left context + target] sequences, and one is used for the [target + right context] sequences.
- Dense layer:
We concate the 2 hidden states from the LSTM layers and feed it into the Dense layer.
The only difference compared to the TD-LSTM is its input. The input of TC-LSTM is a concatenation of the input word vector and the \(v_{target}\) vector. We calculate the \(v_{target}\) vector by averaging the all the target word vector(s) of the sample. For example, if the target in the sentence is jimmy carter, we tokenizer the target to jimmy and carter then convert them to word vector. After that, we average those vector to get the \(v_{target}\) vector.
An overview of TC-LSTM is illustrated in Figure 2. The model extends TD-LSTM by incorporating an target con- nection component, which explicitly utilizes the connections between target word and each context word when composing the representation of a sentence.
The input of TC-LSTM is a sentence consist- ing of n words { \(w_1,w_2,...w_n\) } and a target string t occurs in the sentence. We represent target t as { \(w_{l+1}, w_{l+2}...w_{r−1}\) } because a target could be a word sequence of variable length, such as “google” or “harry potter”. When processing a sentence, we split it into three components: target words, preceding context words and following context words. We obtain target vector \(v_{target}\) by averaging the vectors of words it contains, which has been proven to be simple and effective in representing named entities (Socher et al., 2013a; Sun et al., 2015). When compute the hidden vectors of preceding and following context words, we use two separate long short-term memory models, which are similar with the strategy used in TD-LSTM. The difference is that in TC-LSTM the input at each position is the concatenation of word embedding and target vector vtarget, while in TD-LSTM the input at each position only includes only the embedding of current word.
The input data has an additional element which is the \(v_{target}\) vector. Let create a new Dataset class for TC-LSTM.
from IPython.display import Image
Image(filename='images/figure_2_image.png')
class TCLSTM(pl.LightningModule):
def __init__(self, embeddings, hidden_size, num_layers=1, num_classes=3, batch_first=True, lr=1e-3, dropout=0, l2reg=0.01):
super().__init__()
embedding_dim = embeddings.shape[1]
self.embedding = nn.Embedding.from_pretrained(embeddings) # load pre-trained word embeddings
self.l_lstm = nn.LSTM(embedding_dim*2, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.r_lstm = nn.LSTM(embedding_dim*2, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.linear = nn.Linear(hidden_size*2, num_classes)
self.lr = lr
self.l2reg = l2reg
# log hyperparameters
# self.save_hyperparameters()
# Define metrics
self.train_acc = torchmetrics.Accuracy()
self.val_acc = torchmetrics.Accuracy()
self.val_f1 = torchmetrics.F1(num_classes=3, average='macro')
self.test_acc = torchmetrics.Accuracy()
self.test_f1 = torchmetrics.F1(num_classes=3, average='macro')
def configure_optimizers(self):
optim = torch.optim.Adam(self.parameters(), lr=self.lr, weight_decay=self.l2reg)
return optim
def forward(self, data):
cols = ['padded_l_sequence', 'padded_r_sequence', 'l_len', 'r_len', 'padded_target_sequence']
padded_l_seqs, padded_r_seqs, l_lens, r_lens, padded_target_seqs = [data[col] for col in cols]
# convert seq to word vector
padded_l_embeds = self.embedding(padded_l_seqs)
padded_r_embeds = self.embedding(padded_r_seqs)
padded_target_embeds = self.embedding(padded_target_seqs) # BxLxH
# create v_target vector and concat it to both l_embeds and r_embeds
v_targets = torch.mean(padded_target_embeds, dim=1, keepdims=True)
padded_l_embeds = torch.cat((padded_l_embeds, v_targets.expand((-1, padded_l_embeds.shape[1], -1))), dim=2)
padded_r_embeds = torch.cat((padded_r_embeds, v_targets.expand((-1, padded_r_embeds.shape[1], -1))), dim=2)
# pack the embeds
padded_l_seq_pack = pack_padded_sequence(padded_l_embeds, l_lens.cpu(), batch_first=True, enforce_sorted=False)
padded_r_seq_pack = pack_padded_sequence(padded_r_embeds, r_lens.cpu(), batch_first=True, enforce_sorted=False)
_, (h_l, _) = self.l_lstm(padded_l_seq_pack)
_, (h_r, _) = self.r_lstm(padded_r_seq_pack)
h = torch.cat((h_l[-1], h_r[-1]), -1) # B x 2H
out = self.linear(h)
return out
def training_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.train_acc(scores, sentiments)
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
self.log('train_acc', self.train_acc, on_step=True, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.val_acc(scores, sentiments)
self.val_f1(scores, sentiments)
self.log('val_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('val_acc', self.val_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
self.log('val_f1', self.val_f1, on_step=False, on_epoch=True, prog_bar=True, logger=True)
def test_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
scores = F.softmax(logits, dim=-1)
self.test_acc(scores, sentiments)
self.test_f1(scores, sentiments)
self.log('test_acc', self.test_acc, on_step=False, on_epoch=True, logger=True)
self.log('test_f1', self.test_f1, on_step=False, on_epoch=True, logger=True)LSTM
This is just a simple LSTM model with a embedding layer, 1 LSTM layers and 1 dense layer.
For the input data, we simply feed all the input word vector to the LSTM without informing the model any information of the target words.
The LSTM model solves target-dependent sentiment classification in a target- independent way. That is to say, the feature representation used for sentiment classification remains the same without considering the target words. Let us again take “I bought a new camera. The picture quality is amazing but the battery life is too short” as an example. The representations of this sentence with regard to picture quality and battery life are identical. This is evidently problematic as the sentiment polarity labels towards these two targets are different.
from IPython.display import Image
Image(filename='images/figure_3_image.png')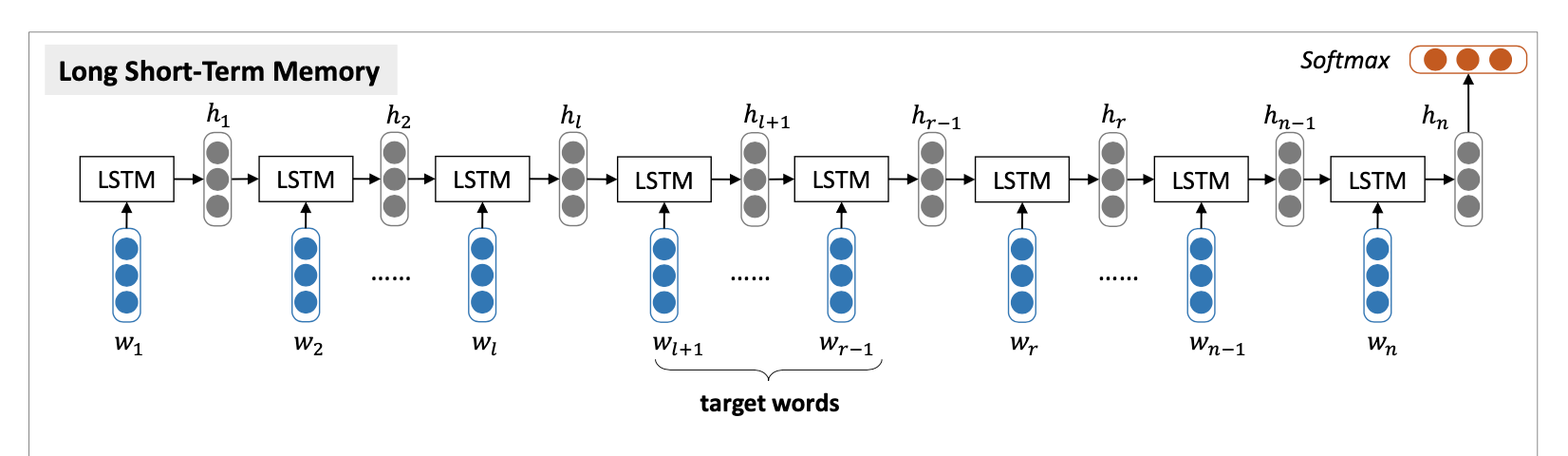
class LSTM(pl.LightningModule):
def __init__(self, embeddings, hidden_size, num_layers=1, num_classes=3, batch_first=True, lr=1e-3, dropout=0, l2reg=0.01):
super().__init__()
embedding_dim = embeddings.shape[1]
self.embedding = nn.Embedding.from_pretrained(embeddings) # load pre-trained word embeddings
self.lstm = nn.LSTM(embedding_dim, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.linear = nn.Linear(hidden_size, num_classes)
self.lr = lr
self.l2reg = l2reg
# Define metrics
self.train_acc = torchmetrics.Accuracy()
self.val_acc = torchmetrics.Accuracy()
self.val_f1 = torchmetrics.F1(num_classes=3, average='macro')
self.test_acc = torchmetrics.Accuracy()
self.test_f1 = torchmetrics.F1(num_classes=3, average='macro')
def configure_optimizers(self):
optim = torch.optim.Adam(self.parameters(), lr=self.lr, weight_decay=self.l2reg)
return optim
def forward(self, data):
cols = ['padded_sequence', 'len']
padded_seqs, lens = [data[col] for col in cols]
# convert seq to word vector
padded_embeds = self.embedding(padded_seqs)
# pack the embeds
padded_seq_pack = pack_padded_sequence(padded_embeds, lens.cpu(), batch_first=True, enforce_sorted=False)
_, (h, _) = self.lstm(padded_seq_pack)
out = self.linear(h[-1])
return out
def training_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.train_acc(scores, sentiments)
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('train_acc', self.train_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.val_acc(scores, sentiments)
self.val_f1(scores, sentiments)
self.log('val_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('val_acc', self.val_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
self.log('val_f1', self.val_f1, on_step=False, on_epoch=True, prog_bar=True, logger=True)
def test_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
scores = F.softmax(logits, dim=-1)
self.test_acc(scores, sentiments)
self.test_f1(scores, sentiments)
self.log('test_acc', self.test_acc, on_step=False, on_epoch=True, logger=True)
self.log('test_f1', self.test_f1, on_step=False, on_epoch=True, logger=True)Training
First of all we will load the pre-trained word embedding Glove. We use the same one with the author.
We use 100-dimensional Glove vectors learned from Twitter, randomize the parameters with uniform distribution U(−0.003,0.003), set the clipping threshold of softmax layer as 200 and set learning rate as 0.01.
Since the author does not provide explicitly the hyper-parameters he used, we have to fine-tune a bit to get good result.
# Load pretrained word embedding GLOVE.
word_embeddings = load_pretrained_word_embeddings({"name": "twitter.27B", "dim": 100}).vector_cache/glove.twitter.27B.zip: 1.52GB [04:53, 5.18MB/s]
100%|█████████▉| 1191916/1193514 [00:43<00:00, 27135.96it/s]# Download dataset
download_url(TRAIN_DS_URL, "train.raw", "download/raw_data")
download_url(TEST_DS_URL, "test.raw", "download/raw_data")
train_data = _load_data_from("download/raw_data/train.raw")
test_data = _load_data_from("download/raw_data/test.raw")
# Build vocabulary for the dataset
all_sentences = train_data[0] + test_data[0]
all_targets = train_data[1] + test_data[1]
tokenizer = Tokenizer(get_tokenizer("basic_english"))
build_vocab(tokenizer, [all_sentences, all_targets])
# Create datamodule
options = {
"on_gpu": True,
"batch_size": 64,
"num_workers": 2
}
datamodule = Twitter(tokenizer, options)
# Create embedding matrix
embedding_matrix = create_embedding_matrix(word_embeddings, tokenizer.vocab, "embedding_matrix.dat")TD-LSTM
# Define callback
checkpoint_callback = ModelCheckpoint(
monitor='val_acc', # save the model with the best validation accuracy
dirpath='checkpoints',
mode='max',
)
tb_logger = pl_loggers.TensorBoardLogger('logs/') # create logger for tensorboard
# Set hyper-parameters
lr = 1e-3
hidden_size = 300
num_epochs = 30
l2reg = 0.0
trainer = pl.Trainer(gpus=1, max_epochs=num_epochs, logger=tb_logger, callbacks=[checkpoint_callback], deterministic=True)
# trainer = pl.Trainer(fast_dev_run=True) #Debug
# trainer = pl.Trainer(overfit_batches=0.1, max_epochs=30) #Debug
model = TDLSTM(embedding_matrix, hidden_size, lr=lr, l2reg=l2reg)
trainer.fit(model, datamodule)GPU available: True, used: True
TPU available: False, using: 0 TPU coresloading embedding matrix from embedding_matrix.datLOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
----------------------------------------
0 | embedding | Embedding | 1.3 M
1 | l_lstm | LSTM | 482 K
2 | r_lstm | LSTM | 482 K
3 | linear | Linear | 1.8 K
4 | train_acc | Accuracy | 0
5 | val_acc | Accuracy | 0
6 | val_f1 | F1 | 0
7 | test_acc | Accuracy | 0
8 | test_f1 | F1 | 0
----------------------------------------
966 K Trainable params
1.3 M Non-trainable params
2.3 M Total params
9.235 Total estimated model params size (MB)Global seed set to 2401# load the best model and evaluate on the testset
new_model = TDLSTM.load_from_checkpoint(checkpoint_callback.best_model_path, embeddings=embedding_matrix, hidden_size=300)
trainer.test(new_model, datamodule.test_dataloader())LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'test_acc': 0.6979768872261047, 'test_f1': 0.6850955486297607}
--------------------------------------------------------------------------------[{'test_acc': 0.6979768872261047, 'test_f1': 0.6850955486297607}]TC-LSTM
checkpoint_callback_2 = ModelCheckpoint(
monitor='val_acc', # save the model with the best validation accuracy
dirpath='checkpoints',
mode='max',
)
tb_logger = pl_loggers.TensorBoardLogger('logs/') # create logger for tensorboard
# Set hyper-parameters
lr = 1e-3
hidden_size = 300
num_epochs = 30
l2reg = 0.0
trainer = pl.Trainer(gpus=1, max_epochs=num_epochs, logger=tb_logger, callbacks=[checkpoint_callback_2])
# trainer = pl.Trainer(fast_dev_run=True) #Debug
# trainer = pl.Trainer(overfit_batches=0.1, max_epochs=30) #Debug
model = TCLSTM(embedding_matrix, hidden_size, lr=lr, l2reg=l2reg)
trainer.fit(model, datamodule)GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
----------------------------------------
0 | embedding | Embedding | 1.3 M
1 | l_lstm | LSTM | 602 K
2 | r_lstm | LSTM | 602 K
3 | linear | Linear | 1.8 K
4 | train_acc | Accuracy | 0
5 | val_acc | Accuracy | 0
6 | val_f1 | F1 | 0
7 | test_acc | Accuracy | 0
8 | test_f1 | F1 | 0
----------------------------------------
1.2 M Trainable params
1.3 M Non-trainable params
2.5 M Total params
10.195 Total estimated model params size (MB)Global seed set to 2401# load the best model and evaluate on the testset
new_model = TCLSTM.load_from_checkpoint(checkpoint_callback_2.best_model_path, embeddings=embedding_matrix, hidden_size=300)
trainer.test(new_model, datamodule.test_dataloader())LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'test_acc': 0.7008670568466187, 'test_f1': 0.6788402199745178}
--------------------------------------------------------------------------------[{'test_acc': 0.7008670568466187, 'test_f1': 0.6788402199745178}]LSTM
checkpoint_callback_3 = ModelCheckpoint(
monitor='val_acc', # save the model with the best validation accuracy
dirpath='checkpoints',
mode='max',
)
tb_logger = pl_loggers.TensorBoardLogger('logs/') # create logger for tensorboard
# Set hyper-parameters
lr = 1e-3
hidden_size = 300
num_epochs = 30
l2reg = 0.0
trainer = pl.Trainer(gpus=1, max_epochs=num_epochs, logger=tb_logger, callbacks=[checkpoint_callback_3])
# trainer = pl.Trainer(fast_dev_run=True) #Debug
# trainer = pl.Trainer(overfit_batches=0.1, max_epochs=30) #Debug
model = LSTM(embedding_matrix, hidden_size, lr=lr, l2reg=l2reg)
trainer.fit(model, datamodule)GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
----------------------------------------
0 | embedding | Embedding | 1.3 M
1 | lstm | LSTM | 482 K
2 | linear | Linear | 903
3 | train_acc | Accuracy | 0
4 | val_acc | Accuracy | 0
5 | val_f1 | F1 | 0
6 | test_acc | Accuracy | 0
7 | test_f1 | F1 | 0
----------------------------------------
483 K Trainable params
1.3 M Non-trainable params
1.8 M Total params
7.302 Total estimated model params size (MB)Global seed set to 2401# load the best model and evaluate on the testset
new_model = LSTM.load_from_checkpoint(checkpoint_callback_3.best_model_path, embeddings=embedding_matrix, hidden_size=300)
trainer.test(new_model, datamodule.test_dataloader())LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'test_acc': 0.6878612637519836, 'test_f1': 0.6633064150810242}
--------------------------------------------------------------------------------[{'test_acc': 0.6878612637519836, 'test_f1': 0.6633064150810242}]Discussion
Our result:
| Method | Accuracy | Macro-F1 |
|---|---|---|
| LSTM | 0.687 | 0.66 |
| TD-LSTM | 0.697 | 0.685 |
| TC-LSTM | 0.7 | 0.679 |
Paper result:
| Method | Accuracy | Macro-F1 |
|---|---|---|
| LSTM | 0.665 | 0.647 |
| TD-LSTM | 0.708 | 0.690 |
| TC-LSTM | 0.715 | 0.695 |
Firstly, compared to the result from the paper, our implementation gets very close results. You can try to tune the model to get a better result.
Secondly, it is surprising that we can get a much better result with the simple LSTM model compared to the paper result. The reason that the LSTM can get a very close result compared to TD-LSTM and TC-LSTM is explainable. Even though this is the target-dependent sentiment classification task, there is only one target per sentence in the dataset. Therefore, the target information is redundant in this case. The LSTM model can use the surrounding words to classify the sentence.
You can read more about the paper here
from IPython.display import Image
Image(filename='images/results.png')
Lessons
Even though the embedding layer is frozen during traning (parameters not updated), using the corpus vocab to create embedding matrix from pretrained Glove yield better result than using the whole word embeddings for the embedding layer.
Using pad_sequence and pack_padded_sequence assure the LSTM/RNN/GRU not processing the padding token. It is better than padding with max length. The result of 2 methods are the same. From what I search, padding with max length will adversely affect the performance of the model. Even though, we can set the loss function to not to account for the padding token, the padding token still have affect on the input tokens. The reason may be that the latter will process the padding token together with the input ones.
Consider the structure of the project before coding it to save refactoring time.